Terraform Depends On Success
Posted on April 16, 2025 by Michael Keane Galloway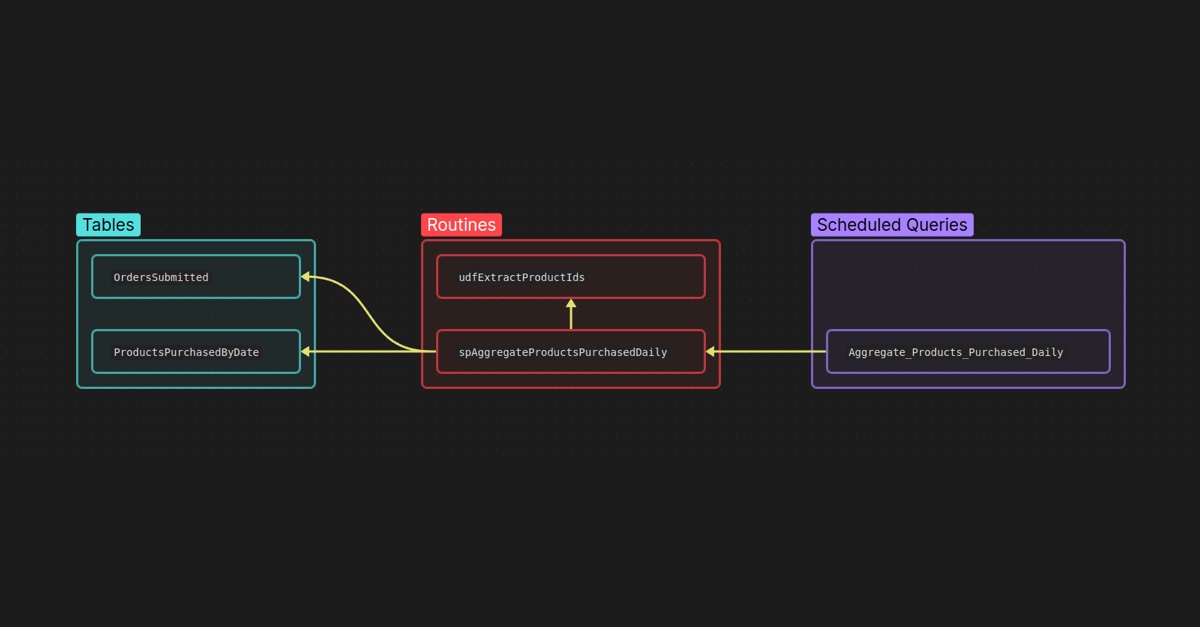
My team has been working on modernizing our data engineering and business intelligence processes. We have started to build Terraform modules for tracking the tables, stored procedures, scheduled queries etc that we deploy to BigQuery. Through iterating on these modules, our team forgot to capture the dependency information for the new entities that we were creating. Since we started with entities that already existed and mostly grafted on new entities we didn’t really track the dependencies. That meant that when we started deploying new modules with green field entities, we ended up having to double run our Terraform deployment to build out all of the entities that were missed in the first failing run.
As an example, let’s consider a simple analytics process that looks at order submissions and aggregates products purchased by day. Our general architecture would produce something like the following:
- A table with a pivot by date of
OrdersSubmitted. - A user defined function for extracting the products from the Order called
udfExtractProductIds. - A stored procedure to encapsulate our process of building this data called
spAggregateProductsPurchasedDaily. - A scheduled query to orchestrate the running of the stored procedure daily
called “Aggregate Products Purchased Daily
<Enviornment>”. - Another pivot table with product counts purchased by date called
ProductsPurchasedByDate.
That would result in the following abbreviated Terraform:
resource "google_bigquery_table" "OrdersSubmitted" {
dataset = var.dataset[terraform.workspace]
id = "OrdersSubmitted"
# abbreviated to save space in this example.
}
resource "google_bigquery_table" "ProductsPurchasedByDate" {
dataset = var.dataset[terraform.workspace]
id = "ProductsPurchasedByDate"
# abbreviated to save space in this example.
}
resource "google_bigquery_routine" "udfExtractProductIds" {
dataset = var.dataset[terraform.workspace]
id = "udfExxtractProductIds"
# abbreviated to save space in this example.
}
resource "google_bigquery_routine" "spAggregateProductsPurchasedDaily" {
dataset = var.dataset[terraform.workspace]
id = "spAggregateProductsPurchasedDaily"
# abbreviated to save space in this example.
}
resource "google_bigquery_job" "Aggregate_Products_Purchased_Daily" {
job_id = "Aggregate Products Purchased Daily ${terraform.workspace}"
# abbreviated to save space in this example.
}
When something like this gets deployed, Terraform has no idea what the dependencies are between the entities. It might attempt to deploy the stored procedure before it deploys the tables, which leads to the DML referencing tables that don’t exist causing an error that will lead to the stored procedure not being deployed. When this happens, it has been my experience that the tables will get created by the first run, and the second Terraform apply will deploy the stored procedure.
Because we were creating this issue within our Terraform modules, I had a frustrating time as our team’s release engineer for a recent sprint. It felt like I had to double run all of Terraform deployments for BigQuery. That led me to make the observation that we’re having this problem in our release thread on Teams. I then had a quick direct chat with our team’s data engineer that I think we’re going to have to do something to try and improve this, and jotted down some quick notes for when the opportunity to start incrementally fixing this problem presented itself within the next sprint.
The solution that I documented in my notes would be to use the depends_on
attribute that can be added to any resource. That way Terraform can build a
dependency graph for our resources and schedule the application of our
declarations. With the above example in mind, my solution would look something
like this:
resource "google_bigquery_table" "OrdersSubmitted" {
dataset = var.dataset[terraform.workspace]
id = "OrdersSubmitted"
# abbreviated to save space in this example.
}
resource "google_bigquery_table" "ProductsPurchasedByDate" {
dataset = var.dataset[terraform.workspace]
id = "ProductsPurchasedByDate"
# abbreviated to save space in this example.
}
resource "google_bigquery_routine" "udfExtractProductIds" {
dataset = var.dataset[terraform.workspace]
id = "udfExxtractProductIds"
# abbreviated to save space in this example.
}
resource "google_bigquery_routine" "spAggregateProductsPurchasedDaily" {
dataset = var.dataset[terraform.workspace]
id = "spAggregateProductsPurchasedDaily"
depeands_on = [
google_bigquery_table.OrdersSubmitted,
google_bigquery_table.ProductsPurchasedByDate,
google_bigquery_routine.udfExtractProductIds
]
# abbreviated to save space in this example.
}
resource "google_bigquery_job" "Aggregate_Products_Purchased_Daily" {
job_id = "Aggregate Products Purchased Daily ${terraform.workspace}"
depends_on = [
google_bigquery_routine.spAggregateProductsPurchasedDaily
]
# abbreviated to save space in this example.
}
A few days later, our JR developer submitted a pull request with some Terraform
similar to my example above. I put a hold on the pull request, and used my
notes to present him with the problem and my proposed solution. He made the
appropriate changes and his PR was approved. Then a couple of days later, the
data engineer submitted a PR without dependencies, so I repeated the same
process that I had completed with the JR developer. A little while after that,
our manager spotted another PR that was missing a dependency declarations.
Finally when we merged for release at the end of the sprint, I spotted one last
missing depends_on to remedy before we shipped. I made sure to follow up with
SR developer that was the release engineer for this sprint, and we deployed our
BigQuery changes without having to double apply.
I hope this can serve as a useful example of a team finding a solution to a problem, documenting that solution, applying it through peer review, and making a small incremental improvement within a sprint.